Shrink projects to fit leadership turnover rates
A few years back I remember reading about bike infrastructure improvements in Seville, Spain, where the city had built 80 kilometres of protected bicycle lanes in 18 months. (Ottawa’s protected bike lanes on Laurier Ave. and O’Connor St. are 1.5 and 2 kilometres respectively). The key to Seville’s approach was starting and finishing the infrastructure project within a single mayoral political term.
So many urban planning projects fall apart when city or regional government leadership changes take place. (Ottawa’s first attempt at a light-rail system – cancelled in 2006 after being approved by the previous city council – is a good example of this.) Engineering and construction projects can take a decade or more, from initial idea to completion. In Canada (where cities are chronically underfunded, and depend on provincial and federal funding for major infrastructure projects) that can mean two or three elections at each of the three levels of government over the course of a project.
If a project takes 10 years, an unfavourable outcome in just one of up to nine (!) elections could result in it getting paused, cancelled, relitigated or redesigned. There are a lot of examples of this. As the saying goes, that’s why we can’t have nice things.
For urban designers, the Seville approach is valuable because it gives citizens a chance to see the benefits of a project firsthand and in a tangible way. Years’ worth of mockups and project plans on paper don’t have the same effect. Other civic leaders – particularly New York’s former transportation commissioner, Janette Sadik-Khan – have run with this idea by prototyping new bike lanes and protected walking areas using inexpensive concrete barriers and pylons. Doing this demonstrates why something is valuable (especially if it’s controversial), and it can be done practically overnight – much faster and cheaper than, say, digging up and replacing an entire street.

Government IT and the slow failure model
Large government IT projects have an entirely different set of problems, but the same Seville-inspired solution. (And yes, applying urban design ideas to public sector tech is pretty much my favourite.)
Much like major infrastructure projects, government IT projects are typically years long, cost millions of dollars, and are managed using a very linear, waterfall planning process. Even more so than physical infrastructure, government IT projects depend inherently on unpredictable human behaviour: how will people interact with the service the IT project enables? Will they be able to use it? If societal and political priorities change, how quickly can the IT project be updated to match? This human angle is partly why ideas taken from traditional infrastructure – like enterprise architecture, or waterfall planning in general – don’t work well for IT projects.
Government IT projects have a long track record of failure, and waterfall planning is a major root cause. Assumptions about how a system will work – and about how human beings will interact with it – are made without feedback from users, and baked in at the very outset of projects. Detailed project plans and approvals leave little to no room to iterate even when it becomes clear that something is on the wrong track. Complex and burdensome budget and approval requirements incentivize “everything and the kitchen sink” approaches to project design, where creating a large mega-project saves having to go through approval steps multiple times.
Compounding all of this is that most major IT projects outlast the executives that are nominally in charge of them. If a typical government IT project takes 3 to 6 years, from idea to completion, then it might go through two, or three, or four executive leaders at each layer of the management hierarchy. With no one dedicated at the helm, a project’s own momentum can easily carry it along a failure-bound trajectory. For years.
Deputy minister and assistant deputy minister turnover is estimated at 1-3 years in the same department, based on biographical data from announcements on changes in the senior ranks of the public service. For any given large IT project, senior leaders are likely to arrive after it has already started, and depart before it finishes. Being on deck when a project is “completed” and launches is, in fact, something most senior leaders would prefer to avoid – since, for waterfall projects, this is typically the point of first contact with real human users and the moment when a slow failure becomes a politically-damaging failure.
The high rate of leadership turnover and the years-long duration of projects means that no senior leader is personally responsible or accountable for a project’s success. On top of that, public sector organizations tend to create committees to govern or oversee major projects (often involving nested sets of committees at each layer of the management hierarchy). This further diffuses responsibility away from any single actor. As a result, no one individually takes the blame for failure (which is appealing), but no one is able to stop or meaningfully alter the direction of a clearly failure-bound project.
(In the private sector, this tends to look very different; Steve Jobs is the canonical example of a leader with a sense of complete and personal responsibility for every single part of a product. It’s easy to take this too far, as was likely the case for Jobs, but it was very clear who felt accountable for the success or failure of Apple’s products.)
Large government IT projects often end up with convoluted and unclear lines of accountability. They might be shared between several departments; they might have overlapping or conflicting responsibilities between teams within each of those departments. For each team and each department, it’s not unusual for everyone involved to say “our part worked” even when the project ends in disaster. These convoluted lines of accountability happen because no one wants to make difficult decisions about intra- or inter-departmental ownership of the project – where good outcomes require saying no to people. Instead, you end up with a massive set of involved stakeholders and organizational dependencies. Let that play out over several years – where each of the individual people involved changes several times, while the project continues apace – and it becomes a surprise when projects occasionally work out after all. Failure is the regular outcome.
Smaller and better
What does doing this better look like? There’s two overall remedies:
- Reducing the number of stakeholders and oversight actors involved in a project
- Shrinking the project timeline so that it fits into a smaller number of leadership turnover cycles (ideally, one)
In the first case, this includes eliminating committees, delegating decision-making powers down as close as possible to the product team actually doing the work, and removing dependencies on other teams and other departments (including, if you have one, your centralized IT infrastructure department). Each of these is intended to re-gather decision-making responsibilities and accountability to a smaller set of actors (ideally a single empowered leader who is formally responsible for the project achieving successful outcomes).
In the second case, this involves breaking up large projects into smaller pieces, each of which are shorter than the leadership turnover rate of your organization (e.g. less than 2 years, if that’s the average length of time an executive is in the same role). The really important requirement here is that each of those smaller pieces actually adds value on its own, rather than only being useful if all of them are completed at the very end.
Breaking a project into phases that will only be useful when the last phase is finished is “false incrementalism”. To be useful, each of the small projects actually need to be shipped – one at a time, as they’re finished – and deliver tangible value to the public, even if none of the subsequent future phases were to go ahead. There’s a great quote from Dan Milstein (via Paul Ramsey’s excellent Small IT presentation) that captures this:
Fortunately, there’s a very simple test to determine if you’re falling prey to the False Incrementalism: if after each increment, an Important Person were to ask your team to drop the project right at that moment, would the business have seen some value? That is the gold standard.
Shipping small projects regularly over time (instead of one mega-project at the end) has an additional benefit. You get feedback from the public – is it working? is it easy to use? – much earlier than in a traditional waterfall project. You then need to be willing and able to incorporate that feedback and make changes as a result, which is where having a single empowered leader rather than a diffused set of committees is particularly important.
How big is too big?
The research is pretty clear: IT projects larger than $10M have a consistently high rate of failure. Software experts in the US government suggest that, in order to be successful, IT projects should be delivered in less than 6 months and have budgets smaller than $2M.
The best overview of this that I’ve seen is Waldo Jaquith’s presentation to the Michigan Senate from early 2020, it’s a must-watch:
In Canada, we don’t have any consistently-published data on the size and timeline of federal government IT projects. On several occasions, however, Members of Parliament have submitted written questions asking departments for details on government IT projects over $1M. Together these paint a really interesting picture of Government of Canada IT spending.
Over three points in time – 2016, 2019, and 2022 – we can see the total budget and estimated completion date for each project. It’s an imperfect overview, in part since it doesn’t indicate when projects started (to gain a full picture of project timelines). For projects that reappear in more than one response dataset, we can see how their budgets and estimated timelines have changed over time.
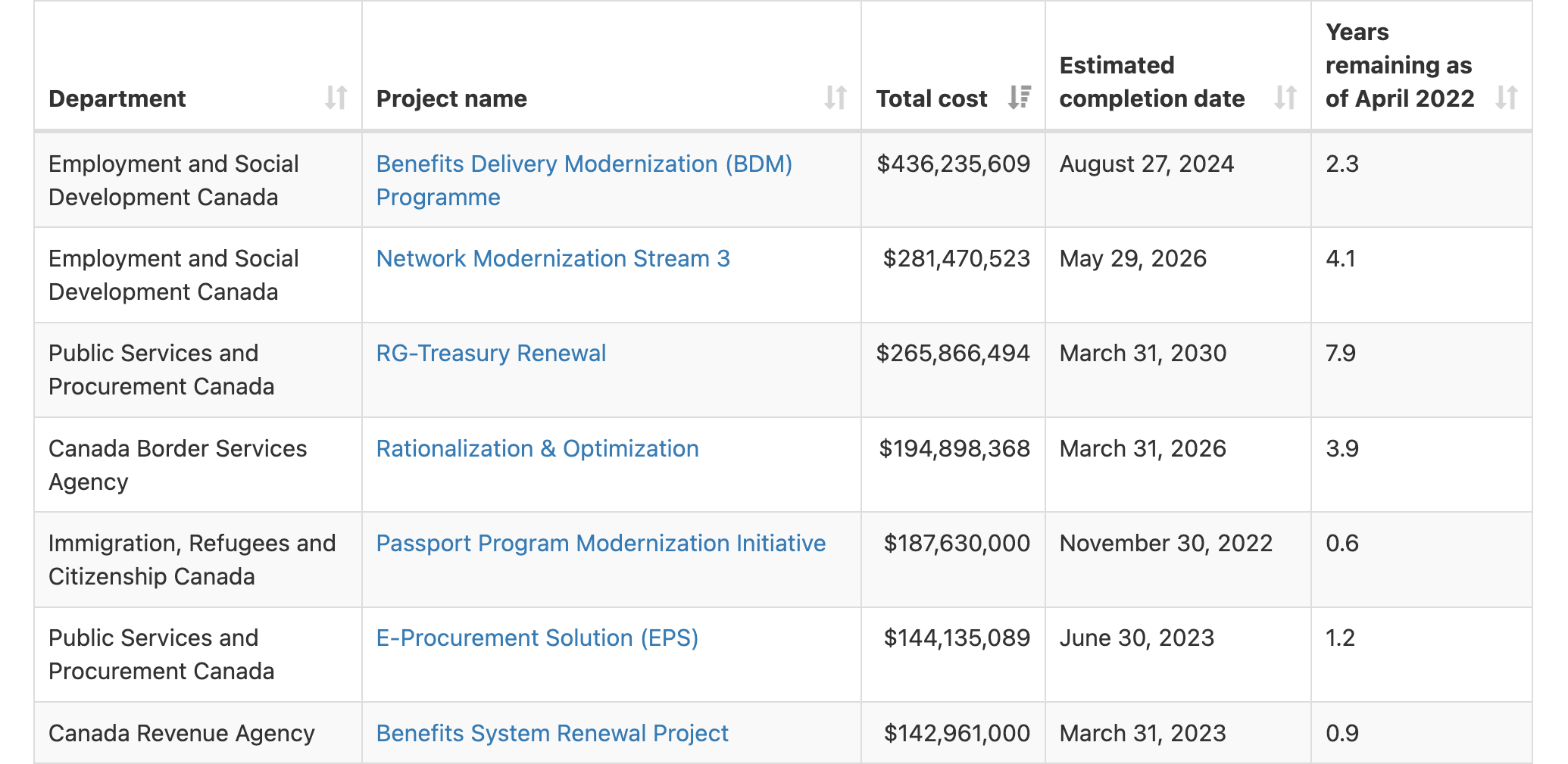
Of the 192 projects that appear in more than one dataset, 86% are behind schedule, 9% are on schedule, and 5% are ahead of schedule based on the estimated completion dates provided.
Looking at the 2022 dataset, the average project duration is somewhere around 3.4 years and the average total budget is $14.6M. We have a long way to go if we want to achieve the recommendation to have projects that are less than 6 months with budgets smaller than $2M.
Making this happen in practice
The problems that governments seek to solve are complex; it’s easy to read this and think “that’s impossible, there’s no way we could achieve this goal in less than 6 months”. The key idea is, figuring out how to break a larger goal down into small, achievable, individually-useful parts.
Let’s take the Phoenix Pay System as an example, every public servant’s favourite project to armchair quarterback (mine too!). Phoenix took 8 years from idea to “completion”, when it launched in 2016, and it’s taken 6 years of work since to get to a place where it works almost smoothly. It was originally budgeted to cost $309M, and by 2018 had cost $1.2B.
What would it look like to deliver Phoenix (or a Phoenix replacement) as a set of small, incremental, less-than-$2M projects that were individually useful? Imagine it’s 2016. Here’s the small pieces that I’d have suggested building:
- A calculator, that ingests a given set of pay information (classification, level, and step; union dues; leave information, etc.) and returns an example paystub for the requested date (approx. 6 months to implement)
- This could be done for one collective agreement group at a time, written in an easy to understand scripting language (such as Python), fully open source.
- Once a single collective agreement group’s set of pay rules was integrated, I’d run it as an online service where public servants could input their own pay situation (or an example situation) and generate example paystubs. It would be useful from this point on as a way of checking if existing paystubs (from Phoenix or its predecessor systems) were accurate, or if there were any errors in the calculator’s own pay rules.
- Entering each collective agreement’s pay rules would be a painstaking, but straightforward process. Making these open source would be critical, since it would let public servants at large confirm that they’re calculated properly (something, let’s be real, we’d all be highly motivated to do!)
- A database, to store public servants’ pay information (approx. 3 months to implement, plus 9 to 12 months for security assessments and approvals)
- This would be built using an open source database (such as Postgres), hosted by a managed cloud service provider, with extensive audit logging and security controls.
- Keeping the calculator (above) as a standalone system that doesn’t store any public servants’ information would allow it to be shipped quickly and publicly tested out in parallel with the longer-term security work for the database.
- A set of API connections and scheduled processes, to ingest updates from departments’ HR databases, send them to the calculator service above, and send the results to payment processing systems to pay public servants each payday (approx. 6 months to build, cumulatively, and 6 to 12 months to test before using in practice).
- A user-friendly interface that lets public servants review their paystubs and pay history (approx. 6 months to build, plus continued iteration over time).
- In practice, an in-house team at PSPC built MyGCPay, a genuinely beautiful version of this several years later. It’s far and away the nicest and most professional online service to emerge from the Phoenix project.
Software systems can be intimidating, but ultimately they all consist of interfaces, data, and math. Each of these are pretty straightforward when you break them down into small enough pieces.
It’s easy to solutionize – especially with several years’ of hindsight! – and the danger of these kinds of exercises is getting too far into detail before learning anything from research with users. (That’s exactly the problem with waterfall planning, too.)
The main takeaway though is that, for any given project, my advice would invariably be: ship it to the public and learn from what happens. Do this as early and as frequently as possible, in a safe environment (e.g. through simulations, beta testing, sample data, clear processes in place to seamlessly revert errors, etc.). Break things into smaller pieces that let you gather feedback sooner, and that provide a tangible benefit to people one step at a time.
If nothing else, then as an IT leader going from one department to the next, you can show that you actually shipped something to the public, and that it actually helped people. All things considered, that’s a rare and wonderful thing.
Postscript: is fast possible?
Whether it’s urban infrastructure or government IT, it’s easy to get stuck thinking that years-long projects are the only possibility. When that’s all we see, it trains us over time to expect that that’s normal.
One of my favourite webpages on the internet is Patrick Collison’s Fast. Patrick is the CEO of Stripe, and his list of fast projects is a great reminder of what’s possible. The Empire State Building was built in 410 days. The 2,700km Alaska Highway was built in 234 days. The Eiffel Tower was built in 2 years and 2 months. The first US jet fighter was designed and built in 143 days. The first version of the Unix operating system was written in 3 weeks.
It can often seem like these kinds of quickly-delivered projects were only possible in the past, unencumbered by modern regulations and social or environmental protections, or accelerated by wars or other global events. To the extent that our regulations and processes slow things down today, I think the answer for major infrastructure projects is the same as for IT projects: break things into smaller parts that are still independently valuable.
If an infrastructure project is going to take a decade, do environmental assessments for several different variations of it, knowing that future decision-makers may choose differently when you’re no longer around. Make them all public. Gift ready-to-go options to your successors. If you’ve been elected into a decision-making role, have the humility to continue imperfect half-finished projects if they’ll deliver greater public good than harm. Do what you can to speed things up. Deliver useful things in incremental steps. Then, once people have had a chance to experience them, get feedback, learn as much as you can, and go from there.